Graphs vs Tables
Per Stephen Few in his book, Show Me the Numbers:
The difference between Tables and Graphs:
Tables: Display used to look up and compare individual values
Graphs: Display used to reveal relationships among whole sets of values and their overall shape
While we typically reach for our graphing tools whenever we want to tell a story with data, we are likely underutilizing tables. We can merge graphs and tables to often get the best of both worlds.
Get started
We can first load our libraries.
Sparklines
Per Wikipedia:
A sparkline is a very small line chart, typically drawn without axes or coordinates. It presents the general shape of the variation (typically over time) in some measurement, such as temperature or stock market price, in a simple and highly condensed way.
A 1999 screenshot of an implementation of sparklines developed around January 1998. The concept was developed by interaction designer Peter Zelchenko in conversation with programmer Michael Medved, while Medved was developing the QuoteTracker application. The product was later sold to Ameritrade.
We can use gtExtras::gt_sparkline() to add an inline sparkline very quickly. A necessary prep step is to first convert from a long data format to a summarized data format, where each row represents one “group” and the data column is now a vector of the values.
mtcars %>%
head()
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
#> Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
#> Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
#> Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
#> Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
#> Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1By using summarize(list_data = list(col_name)) we can create a list-column of ALL the data for that group.
car_summary <- mtcars %>%
dplyr::group_by(cyl) %>%
dplyr::summarize(
mean = mean(mpg),
sd = sd(mpg),
# must end up with list of data for each row in the input dataframe
mpg_data = list(mpg),
.groups = "drop"
)
car_summary
#> # A tibble: 3 × 4
#> cyl mean sd mpg_data
#> <dbl> <dbl> <dbl> <list>
#> 1 4 26.7 4.51 <dbl [11]>
#> 2 6 19.7 1.45 <dbl [7]>
#> 3 8 15.1 2.56 <dbl [14]>
car_summary %>%
arrange(desc(cyl)) %>%
gt() %>%
gtExtras::gt_sparkline(mpg_data) %>%
fmt_number(columns = mean:sd, decimals = 1)
#> Warning: `label_number_si()` was deprecated in scales 1.2.0.
#> Please use the `scale_cut` argument of `label_number()` instead.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.| cyl | mean | sd | mpg_data |
|---|---|---|---|
| 8 | 15.1 | 2.6 | |
| 6 | 19.7 | 1.5 | |
| 4 | 26.7 | 4.5 |
Sparkline alternatives
You can also plot a density-plot or a histogram instead of just a line plot.
car_summary %>%
arrange(desc(cyl)) %>%
gt() %>%
gtExtras::gt_sparkline(mpg_data, type = "density", line_color = "blue",
fill_color = "red") %>%
fmt_number(columns = mean:sd, decimals = 1)| cyl | mean | sd | mpg_data |
|---|---|---|---|
| 8 | 15.1 | 2.6 | |
| 6 | 19.7 | 1.5 | |
| 4 | 26.7 | 4.5 |
car_summary %>%
arrange(desc(cyl)) %>%
gt() %>%
gtExtras::gt_sparkline(mpg_data, type = "histogram", line_color = "black",
fill_color = "grey", bw = 4) %>%
fmt_number(columns = mean:sd, decimals = 1)| cyl | mean | sd | mpg_data |
|---|---|---|---|
| 8 | 15.1 | 2.6 | |
| 6 | 19.7 | 1.5 | |
| 4 | 26.7 | 4.5 |
Inline bars
You can also generate ggplot2 created bar plots inline. Note that keep_column allows you to keep the raw values and the plot inline.
mtcars %>%
dplyr::select(cyl:wt, mpg) %>%
head() %>%
gt() %>%
gt_plt_bar(column = mpg, keep_column = TRUE, width = 35)| cyl | disp | hp | drat | wt | mpg | mpg |
|---|---|---|---|---|---|---|
| 6 | 160 | 110 | 3.90 | 2.620 | 21.0 | |
| 6 | 160 | 110 | 3.90 | 2.875 | 21.0 | |
| 4 | 108 | 93 | 3.85 | 2.320 | 22.8 | |
| 6 | 258 | 110 | 3.08 | 3.215 | 21.4 | |
| 8 | 360 | 175 | 3.15 | 3.440 | 18.7 | |
| 6 | 225 | 105 | 2.76 | 3.460 | 18.1 |
Percent bars
Alternatively, you may prefer the HTML-generated bar plotsfrom gt_plt_bar_pct(). Note that the bars represent a percentage of max, so the largest value will indicate 100% of the row. You can pass raw values that are scaled to a 0-100% range, or pass values between 0 and 100 that represent an existing percent.
mtcars %>%
head() %>%
dplyr::select(cyl, mpg) %>%
dplyr::mutate(mpg_pct_max = round(mpg/max(mpg) * 100, digits = 2),
mpg_scaled = mpg/max(mpg) * 100) %>%
dplyr::mutate(mpg_unscaled = mpg) %>%
gt() %>%
gt_plt_bar_pct(column = mpg_scaled, scaled = TRUE) %>%
gt_plt_bar_pct(column = mpg_unscaled, scaled = FALSE,
fill = "blue", background = "lightblue") %>%
cols_align("center", contains("scale")) %>%
cols_width(4 ~ px(125),
5 ~ px(125))| cyl | mpg | mpg_pct_max | mpg_scaled | mpg_unscaled |
|---|---|---|---|---|
| 6 | 21.0 | 92.11 | ||
| 6 | 21.0 | 92.11 | ||
| 4 | 22.8 | 100.00 | ||
| 6 | 21.4 | 93.86 | ||
| 8 | 18.7 | 82.02 | ||
| 6 | 18.1 | 79.39 |
Inline Win Loss plots
You can also generate really nice looking “Win Loss” plots, similar to the ones used by The Guardian for Soccer outcomes. The code to bring in the data via the nflreadr package is hidden in an expandable tab below.
Bring data in
library(dplyr)
games_df <- nflreadr::load_schedules() %>%
filter(season == 2020, game_type == "REG") %>%
select(game_id, team_home = home_team, team_away = away_team, result, week) %>%
tidyr::pivot_longer(contains('team'), names_to = 'home_away', values_to = 'team', names_prefix = 'team_') %>%
mutate(
result = ifelse(home_away == 'home', result, -result),
win = ifelse(result == 0 , 0.5, ifelse(result > 0, 1, 0))
) %>%
select(week, team, win) %>%
mutate(
team = case_when(
team == 'STL' ~ 'LA',
team == 'OAK' ~ 'LV',
team == 'SD' ~ 'LAC',
T ~ team
)
)
team_df <- nflreadr::load_teams() %>%
select(team_wordmark, team_abbr, team_conf, team_division)
joined_df <- games_df %>%
group_by(team) %>%
summarise(
Wins = length(win[win==1]),
Losses = length(win[win==0]),
outcomes = list(win), .groups = "drop") %>%
left_join(team_df, by = c("team" = "team_abbr")) %>%
select(team_wordmark, team_conf, team_division, Wins:outcomes)
final_df <- joined_df %>%
filter(team_conf == "AFC") %>%
group_by(team_division) %>%
arrange(desc(Wins)) %>%
ungroup() %>%
arrange(team_division) %>%
select(-team_conf) %>%
mutate(team_division = stringr::str_remove(team_division, "AFC |NFC ")) %>%
mutate(
team_division = factor(team_division,
levels = c("North", "South", "East", "West")
)
) %>%
arrange(team_division)Note that we have a list-column of the outcomes for each team.
glimpse(final_df)
#> Rows: 16
#> Columns: 5
#> $ team_wordmark <chr> "https://github.com/nflverse/nflfastR-data/raw/master/wo…
#> $ team_division <chr> "North", "North", "North", "North", "South", "South", "S…
#> $ Wins <int> 12, 11, 11, 4, 11, 11, 4, 1, 13, 10, 7, 2, 14, 8, 7, 5
#> $ Losses <int> 4, 5, 5, 11, 5, 5, 12, 15, 3, 6, 9, 14, 2, 8, 9, 11
#> $ outcomes <list> <1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0>, <1, 1,…And now we can generate an example table!
final_df %>%
gt(groupname_col = "team_division") %>%
cols_label(team_wordmark = "") %>%
cols_align("left", team_division) %>%
gtExtras::gt_plt_winloss(outcomes, max_wins = 16, type = "pill") %>%
gtExtras::gt_img_rows(columns = team_wordmark, height = 20) %>%
gtExtras::gt_theme_538() %>%
tab_header(
title = gtExtras::add_text_img(
"2020 Results by Division",
url = "https://github.com/nflverse/nflfastR-data/raw/master/AFC.png",
height = 30
)
) %>%
tab_options(data_row.padding = px(2))|
2020 Results by Division
 |
|||
|---|---|---|---|
| Wins | Losses | outcomes | |
| North | |||
 |
12 | 4 | |
 |
11 | 5 | |
 |
11 | 5 | |
 |
4 | 11 | |
| South | |||
 |
11 | 5 | |
 |
11 | 5 | |
 |
4 | 12 | |
 |
1 | 15 | |
| East | |||
 |
13 | 3 | |
 |
10 | 6 | |
 |
7 | 9 | |
 |
2 | 14 | |
| West | |||
 |
14 | 2 | |
 |
8 | 8 | |
 |
7 | 9 | |
 |
5 | 11 | |
Inline bar plots
We can also do inline bar plots, purely via HTML! You can customize the colors, and have the option to scale or use unscaled values.
gt_bar_plot_tab <- mtcars %>%
head() %>%
dplyr::select(cyl, mpg) %>%
dplyr::mutate(
mpg_pct_max = round(mpg / max(mpg) * 100, digits = 2),
mpg_scaled = mpg / max(mpg) * 100
) %>%
dplyr::mutate(mpg_unscaled = mpg) %>%
gt() %>%
gt_plt_bar_pct(column = mpg_scaled, scaled = TRUE) %>%
gt_plt_bar_pct(column = mpg_unscaled, scaled = FALSE, fill = "blue", background = "lightblue") %>%
cols_align("center", contains("scale")) %>%
cols_width(
4 ~ px(125),
5 ~ px(125)
)
gt_bar_plot_tab| cyl | mpg | mpg_pct_max | mpg_scaled | mpg_unscaled |
|---|---|---|---|---|
| 6 | 21.0 | 92.11 | ||
| 6 | 21.0 | 92.11 | ||
| 4 | 22.8 | 100.00 | ||
| 6 | 21.4 | 93.86 | ||
| 8 | 18.7 | 82.02 | ||
| 6 | 18.1 | 79.39 |
Stacked Percent bar charts
We can create a horizontal stacked percent bar chart inline like so. The data can be prepped as seen in the expandable section below.
library(dplyr)
library(tidyr)
library(gt)
player_df <- tibble(
player = c(
"Evan Mobley",
"Sandro Mamukelashvili",
"Charles Bassey",
"Luke Garza",
"Moses Wright",
"Neemias Queta",
"Isaiah Jackson",
"Day'Ron Sharpe"
),
team = c(
"USC", "Seton Hall", "Western Kentucky",
"Iowa", "Georgia Tech", "Utah St", "Kentucky",
"North Carolina"
),
ht = c(
"7'0\"",
"6'10\"",
"6'10\"",
"6'11\"",
"6'9\"",
"7'1\"",
"6'11\"",
"6'10\""
),
dk_pct_time = c(40, 48, 50, 50, 51, 55, 60, 66),
dk_pps = c(1.62, 1.02, 1.54,1.33,1.46,1.37,1.33,1.18),
tip_pct_time = c(26, 10, 19, 15, 25, 27, 15, 24),
tip_pps = c(0.88, .97,1,1.05, .63, .85, .76, .84),
jmp_pct_time = c(33, 42, 31, 35, 25, 18, 25, 10),
jmp_pps = c(.91, .91, .78, 1.04, .86, .74, .71, .42)
) %>%
left_join(
tibble(
player = c(
"Evan Mobley",
"Sandro Mamukelashvili",
"Charles Bassey",
"Luke Garza",
"Moses Wright",
"Neemias Queta",
"Isaiah Jackson",
"Day'Ron Sharpe"
) %>% rep(each = 3),
shot_type = c("Dunks + Lays", "Hooks + Floats", "Jumpers") %>% rep(8)
) %>%
mutate(
shot_type = factor(shot_type, levels = c("Jumpers", "Hooks + Floats", "Dunks + Lays")),
shot_mix = c(
40, 26, 33,
48, 10, 42,
50, 19, 31,
50, 15, 35,
51, 25, 25,
55, 27, 18,
60, 15, 25,
66, 24, 10
)
),
by = "player"
)
basic_tb <- player_df %>%
group_by(player) %>%
summarize(dunks = shot_mix[1], list_data = list(shot_mix)) %>%
arrange(dunks) %>%
gt()
basic_tb %>%
gt_plt_bar_stack(list_data, width = 65,
labels = c("DUNKS", "HOOKS/FLOATS", "JUMPERS"),
palette= c("#ff4343", "#bfbfbf", "#0a1c2b")) %>%
gt_theme_538()| player | dunks | DUNKS||HOOKS/FLOATS||JUMPERS |
|---|---|---|
| Evan Mobley | 40 | |
| Sandro Mamukelashvili | 48 | |
| Charles Bassey | 50 | |
| Luke Garza | 50 | |
| Moses Wright | 51 | |
| Neemias Queta | 55 | |
| Isaiah Jackson | 60 | |
| Day'Ron Sharpe | 66 |
Bullet chart
There’s also an option to create bullet charts which represent a core value and a target metric.
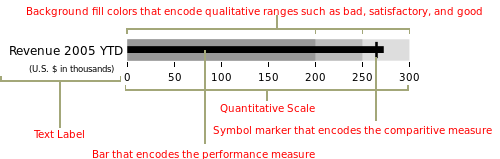
A representative diagram of a bullet chart, where there’s a specific target value represented by a vertical line and a core value represented as a thin bar plot.
set.seed(37)
bullet_df <- tibble::rownames_to_column(mtcars) %>%
dplyr::select(rowname, cyl:drat, mpg) %>%
dplyr::group_by(cyl) %>%
dplyr::mutate(target_col = mean(mpg)) %>%
dplyr::slice_sample(n = 3) %>%
dplyr::ungroup()
bullet_df %>%
gt() %>%
gt_plt_bullet(column = mpg, target = target_col, width = 45,
colors = c("lightblue", "black"))| cyl | disp | hp | drat | mpg | |
|---|---|---|---|---|---|
| Toyota Corolla | 4 | 71.1 | 65 | 4.22 | |
| Fiat X1-9 | 4 | 79.0 | 66 | 4.08 | |
| Merc 240D | 4 | 146.7 | 62 | 3.69 | |
| Hornet 4 Drive | 6 | 258.0 | 110 | 3.08 | |
| Merc 280 | 6 | 167.6 | 123 | 3.92 | |
| Valiant | 6 | 225.0 | 105 | 2.76 | |
| Dodge Challenger | 8 | 318.0 | 150 | 2.76 | |
| Merc 450SL | 8 | 275.8 | 180 | 3.07 | |
| Ford Pantera L | 8 | 351.0 | 264 | 4.22 |
Note that for now, if you want to use any of the gt::fmt_ functions on your column of interest, you’ll need to create a duplicate column ahead of time.
bullet_df %>%
dplyr::mutate(plot_column = mpg) %>%
gt() %>%
gt_plt_bullet(column = plot_column, target = target_col, width = 45) %>%
fmt_number(mpg, decimals = 1)| cyl | disp | hp | drat | mpg | plot_column | |
|---|---|---|---|---|---|---|
| Toyota Corolla | 4 | 71.1 | 65 | 4.22 | 33.9 | |
| Fiat X1-9 | 4 | 79.0 | 66 | 4.08 | 27.3 | |
| Merc 240D | 4 | 146.7 | 62 | 3.69 | 24.4 | |
| Hornet 4 Drive | 6 | 258.0 | 110 | 3.08 | 21.4 | |
| Merc 280 | 6 | 167.6 | 123 | 3.92 | 19.2 | |
| Valiant | 6 | 225.0 | 105 | 2.76 | 18.1 | |
| Dodge Challenger | 8 | 318.0 | 150 | 2.76 | 15.5 | |
| Merc 450SL | 8 | 275.8 | 180 | 3.07 | 17.3 | |
| Ford Pantera L | 8 | 351.0 | 264 | 4.22 | 15.8 |